1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
| import time
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
import re
from pymysql import DatabaseError
from Config import config
import pymysql
def getConnection():
host = config["MYSQL"]["HOST"]
port = int(config["MYSQL"]["PORT"])
db = config["MYSQL"]["DATA_BASE_NAME"]
user = config["MYSQL"]["USERNAME"]
password = config["MYSQL"]["PASSWORD"]
conn = pymysql.connect(host=host, port=port, db=db, user=user, password=password)
return conn
def getAllCharacters():
file_path = './data/hanzi.yaml'
file = open(file_path, 'r', encoding="utf-8")
character_set = set()
for line in file.readlines():
if '\n' in line:
word = line.split('\n')[0]
character_set.add(word)
return character_set
def query(conn, word):
url = 'http://tool.httpcn.com/Zi/So.asp?Tid=1&wd='
wordQuote = urllib.parse.quote(word)
response = urllib.request.urlopen(url + wordQuote, timeout=3)
soup = BeautifulSoup(response, 'html.parser')
one = soup.find('p', attrs={'class': 'text15'}).text
pinyin = None
ft_word = None
kx_word = None
kx_stroke = 0
jt_bushou = None
jt_bushou_stroke = 0
jt_stroke = 0
ft_bushou = None
ft_bushou_stroke = 0
ft_stroke = 0
wuxing = None
jixiong = None
is_changyong = None
if one.__contains__('Setduyin'):
pinyinPatternList = re.findall('拼音:(.+?)Setduyin', one)
else:
pinyinPatternList = re.findall('拼音:(.+?)\s', one)
if len(pinyinPatternList) >= 1:
pinyin = pinyinPatternList[0]
print("拼音为:" + pinyin)
fTWordPatternList = re.findall('繁体字:(.+?)\s', one)
if len(fTWordPatternList) >= 1:
ft_word = fTWordPatternList[0]
print("繁体字 :" + ft_word)
jTBSPatternList = re.findall('简体部首:(.+?)\s', one)
if len(jTBSPatternList) == 0:
jTBSPatternList = re.findall('部首:(.+?)\s', one)
if len(jTBSPatternList) >= 1:
jt_bushou = jTBSPatternList[0]
print("简体部首 :" + jt_bushou)
fTBSPatternList = re.findall('繁体部首:(.+?)\s', one)
if len(fTBSPatternList) >= 1:
ft_bushou = fTBSPatternList[0]
print("繁体部首 :" + ft_bushou)
bsStrokePatternList = re.findall('部首笔画:(.+?)\s', one)
if len(bsStrokePatternList) == 1:
jt_bushou_stroke = int(bsStrokePatternList[0])
print("简体部首笔画 :" + bsStrokePatternList[0])
elif len(bsStrokePatternList) == 2:
jt_bushou_stroke = int(bsStrokePatternList[0])
ft_bushou_stroke = int(bsStrokePatternList[1])
print("简体部首笔画 :" + bsStrokePatternList[0])
print("繁体部首笔画 :" + bsStrokePatternList[1])
strokePatternList = re.findall('总笔画:(\d+)', one)
if len(strokePatternList) == 1:
jt_stroke = int(strokePatternList[0])
print("简体总笔画 :" + strokePatternList[0])
elif len(strokePatternList) == 2:
jt_stroke = int(strokePatternList[0])
print("简体总笔画 :" + strokePatternList[0])
ft_stroke = int(strokePatternList[1])
print("繁体总笔画 :" + strokePatternList[1])
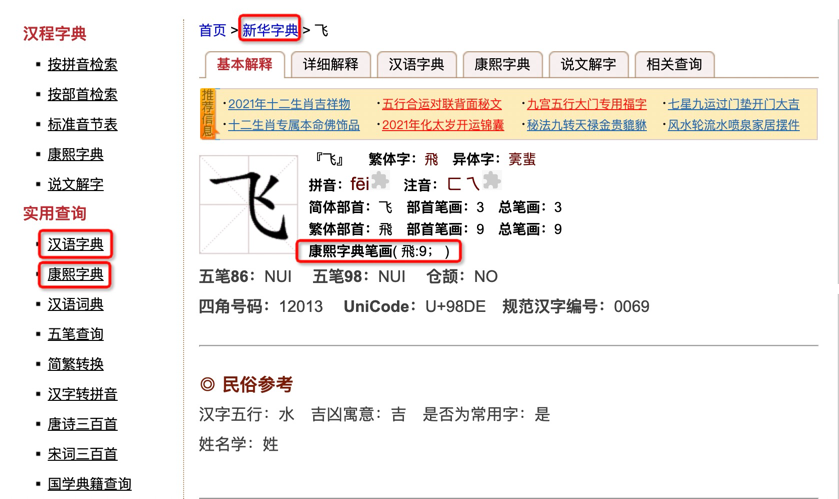
kangxiPatternList = re.findall('康熙字典笔画\( (.+?):(.+?);', one)
if len(kangxiPatternList) >= 1:
kangxi = kangxiPatternList[0]
kx_word = kangxi[0]
kx_stroke = int(kangxi[1])
print("康熙字体 :" + kx_word)
print("康熙笔画 :" + kangxi[1])
two = soup.find('div', attrs={'class': 'text16'}).text
wuxingPatternList = re.findall('汉字五行:(.)', two)
if len(wuxingPatternList) >= 1:
wuxing = wuxingPatternList[0]
print("汉字五行:" + wuxing)
jixiongPatternList = re.findall('吉凶寓意:(.)', two)
if len(jixiongPatternList) >= 1:
jixiong = jixiongPatternList[0]
print("吉凶寓意:" + jixiong)
changyongPatternList = re.findall('是否为常用字:(.)', two)
if len(changyongPatternList) >= 1:
is_changyong = changyongPatternList[0]
print("是否为常用字:" + is_changyong)
if pinyin != None:
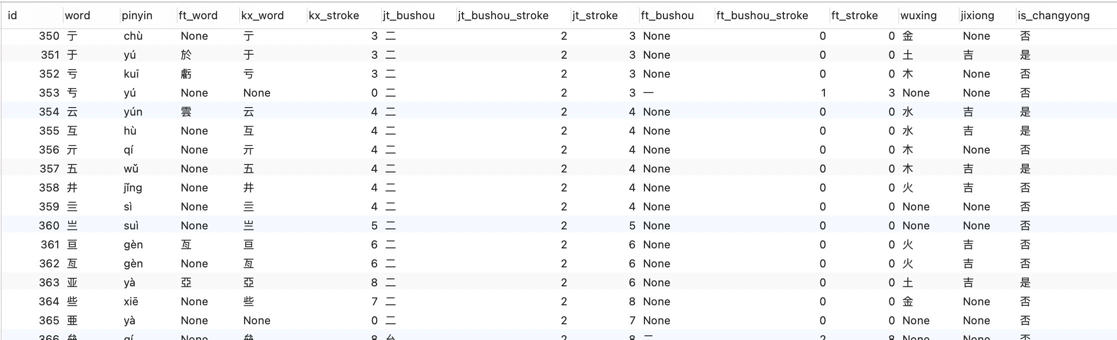
sql_str = f"insert into hancheng (word,pinyin,ft_word,kx_word,kx_stroke,jt_bushou,jt_bushou_stroke,jt_stroke,ft_bushou,ft_bushou_stroke,ft_stroke,wuxing,jixiong,is_changyong) " \
f"values ('{word}', '{pinyin}', '{ft_word}', '{kx_word}', '{kx_stroke}', '{jt_bushou}', '{jt_bushou_stroke}', '{jt_stroke}', '{ft_bushou}', '{ft_bushou_stroke}', '{ft_stroke}', '{wuxing}', '{jixiong}', '{is_changyong}')"
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_str)
conn.commit()
if __name__ == '__main__':
conn = getConnection()
words = getAllCharacters()
for word in words:
try:
query(conn, word)
except Exception as e:
print(e)
if not (isinstance(e, DatabaseError) and e.args.__len__() >= 1 and e.args[0] == 1062):
try:
sql_str = f"insert into hancheng_error2 (word) values ('{word}')"
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_str)
conn.commit()
except Exception as e2:
print(f"数据库已经存在 : " + word)
print('----------------------------------------')
time.sleep(3)
|